Table of Contents
Table of Contents
Images are no longer just visual assets. They are searchable, rankable, and measurable components of modern search ecosystems. When users perform a Google image search, they are interacting with a separate layer of search results that follows its own ranking logic and layout behavior.
Extracting that data manually is unreliable. The image SERP results are dynamically generated, influenced by location, device type, and query variations. Without a structured method, attempts to scrape Google Images often return incomplete or inconsistent data.
This is where a Google Image Scraper API becomes essential. Instead of relying on unstable scripts or manual inspection, it provides controlled access to structured image search data. A reliable Google Image Scraper API ensures that image ranking positions, source URLs, thumbnails, and related metadata are captured accurately and consistently.
For teams working with visual datasets, competitive analysis, or automation workflows, structured extraction is not optional. It is foundational.
What Is a Google Image Scraper API?
A Google Image Scraper API is a structured solution designed to extract data from Google image search results in a consistent and reliable format. Instead of manually trying to scrape Google Images using unstable scripts, this API handles request processing, result parsing, and structured output automatically.
When someone performs a Google image search, the results page loads dynamically. Thumbnails, high-resolution image URLs, source domains, titles, and ranking positions are generated in real time. A Google Image Scraper API sends controlled queries to retrieve those image SERP results and converts them into clean, usable data such as JSON.
For businesses and developers, this means you can collect image ranking data, track visual visibility, or build datasets without dealing with constant structural changes in the front-end layout.
How a Google Image Scraper API Works
A Google Image Scraper API simulates search requests and retrieves structured image search data. It manages headers, rotation, and rendering so the returned output includes image URLs, source links, thumbnails, and position details. The result is standardized data ready for integration into analytics tools, dashboards, or automation workflows.
Difference Between Google Images API and Raw Scraping
Raw scraping often breaks because Google updates its layout frequently. Scripts fail, IPs get blocked, and extracted fields become inconsistent.
A google images api or image search api is built to handle these changes. It provides stable endpoints, structured responses, and scalable access without manual maintenance.

Understanding Google Image Search Structure
Google image search is not a simple gallery of pictures. It is a structured results environment where images are indexed, ranked, grouped, and displayed based on relevance, context, and user behavior. When working with a Google Image Scraper API, understanding this structure becomes critical because the layout directly affects how data should be extracted and interpreted.
How Google Image Search Delivers Results
When a user enters a query, Google does more than match filenames. It evaluates multiple layers of signals before displaying image SERP results.
Key components include:
- Query relevance based on surrounding page content
- Image alt text and structured data
- Page authority and domain trust
- User engagement patterns
- Visual similarity clustering
Results are loaded dynamically. Thumbnails appear first, and additional metadata becomes visible when selected. A reliable Google Image Scraper API captures both visible and embedded fields within that structure.
Image SERP Results: Metadata You Can Extract
Each image result contains valuable data points beyond the thumbnail itself. Using an image search api, you can extract image URLs, source page links, domain information, titles, snippet context, and image ranking position.
This structured extraction allows teams to analyze visibility patterns across queries without manually reviewing results.
Image Ranking Signals in Visual Search
Image ranking follows logic similar to organic search but includes visual relevance.
Important signals often include:
- Contextual keyword alignment
- Image quality and resolution
- Mobile responsiveness
- Topical authority of the source page
A visual search api framework helps interpret how these signals influence image ranking across different queries.
Why Traditional Methods Fail When You Scrape Google Images
Many developers try to scrape Google Images using basic scripts or browser automation. It may work for a few requests, but it rarely works at scale. Google image search is built to serve users, not automated scraping scripts. Without a structured system like a Google Image Scraper API, failures are common and expensive.
Dynamic Rendering and JavaScript Challenges
Google image search relies heavily on dynamic loading. Image SERP results are rendered using JavaScript, and additional images load as users scroll.
A simple HTML request does not return complete data. Thumbnails, high-resolution image URLs, and ranking positions may not appear in the initial response. When you attempt to scrape Google Images without handling rendering properly, the extracted data is incomplete or inconsistent.
An image search api is designed to process these dynamic layers and return structured output without relying on fragile front-end selectors.
IP Blocking and Rate Limits
Repeated automated requests trigger rate limits. Google monitors unusual traffic patterns, especially when scraping image SERP results at scale.
Common issues include:
- Temporary IP bans
- Request throttling
- Inconsistent response delivery
Without rotating infrastructure and controlled request management, raw scraping quickly becomes unstable.
CAPTCHA and Anti-Bot Systems
Google actively protects its systems with CAPTCHA verification and behavioral detection. Basic scraping scripts often fail once these protections activate.
A reliable google images api or Google Image Scraper API is built to handle these technical barriers, ensuring consistent data extraction without constant maintenance or disruption.
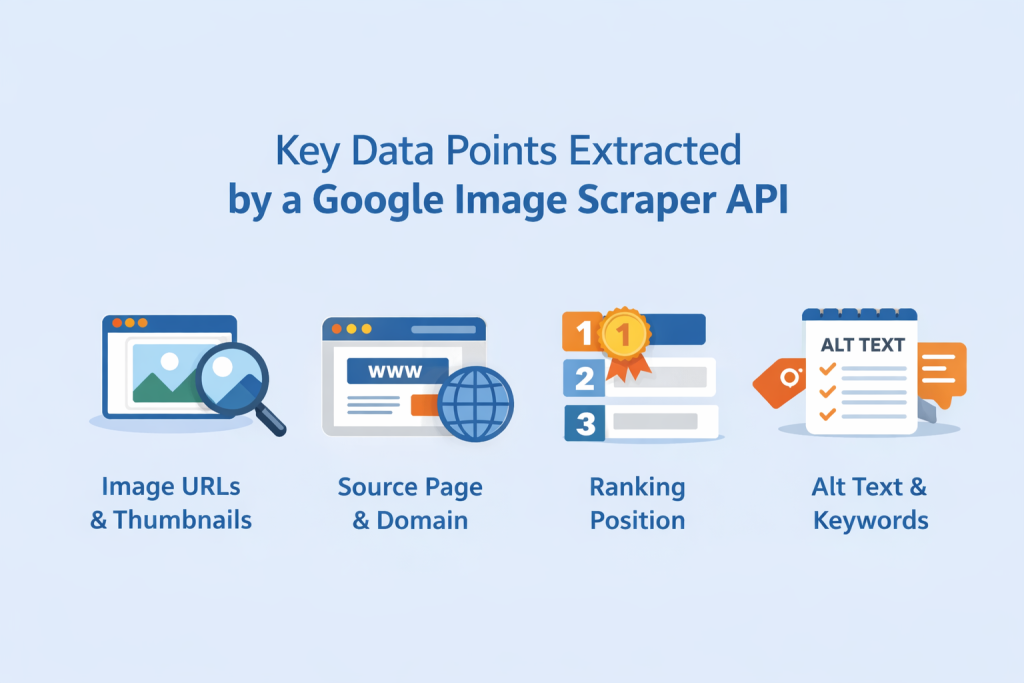
Key Data Points You Can Extract Using an Image Search API
A structured image search api does more than return pictures. It provides organized data from Google image search that can be analyzed, stored, and compared across queries. When powered by a reliable Google Image Scraper API, extraction becomes consistent and usable at scale.
Here are the most valuable data points you can collect.
Image URLs and Thumbnails
The most immediate layer of data includes thumbnail links and direct image URLs. Thumbnails help identify how images appear within image SERP results, while full-resolution URLs allow deeper inspection or dataset collection.
When you scrape Google Images manually, these links are often hidden behind dynamic elements. A Google Image Scraper API extracts them cleanly, preserving structure and order.
Source Page and Domain Data
Every image shown in Google image search is tied to a source page. Extracting the source URL and domain is critical for competitive analysis, attribution tracking, and domain-level monitoring.
This data helps answer practical questions:
- Which domains dominate image ranking for specific queries?
- Are competitors gaining visual visibility?
- How frequently does a brand appear across related searches?
Structured extraction ensures these relationships remain clear.
Image Ranking Position
Position data shows where an image appears within image SERP results. Ranking order matters, especially for high-intent queries.
A Google Image Scraper API captures exact image ranking positions, enabling performance comparison over time without relying on manual checks.
Alt Text and Associated Keywords
Alt attributes and contextual text around an image reveal keyword alignment. Extracting this information through a google images api or image search api helps identify how search engines interpret relevance.
For teams building visual search api models or monitoring visibility trends, these metadata fields provide measurable insight beyond the image itself.

Best Practices for Scraping Google Images at Scale
Scraping a few image SERP results is simple. Scaling that process across thousands of queries is where complexity begins. Without discipline and structure, even a strong Google Image Scraper API setup can become unstable or inefficient. Sustainable extraction requires clear operational practices.
Request Management and Throttling
When you scrape Google Images at scale, request behavior matters. Sending large volumes of simultaneous queries increases the risk of rate limits and interrupted responses.
Effective request management includes:
- Controlled query intervals
- Distributed request patterns
- Monitoring response consistency
- Tracking error rates in real time
A reliable Google Image Scraper API typically handles infrastructure challenges, but configuration still matters. Balanced throttling ensures stable access to Google image search data while maintaining predictable output from your image search api workflows.
Data Cleaning and Deduplication
Raw image SERP results often contain repeated thumbnails, similar images, or near-duplicate entries across related queries. If this data is stored without validation, datasets quickly become inflated and unreliable.
Implement validation rules such as:
- Removing duplicate image URLs
- Normalizing source domains
- Filtering low-resolution or irrelevant files
- Standardizing associated keyword metadata
Clean data improves image ranking analysis and strengthens any visual search api modeling process.
Storing and Structuring Extracted Image Data
Structured storage is critical. Image URLs, ranking position, source domain, alt context, and query parameters should be stored in a relational or well-indexed format.
A properly designed schema allows long-term tracking of image ranking trends and supports scalable analysis. When the Google Image Scraper API output is organized correctly, it becomes a dependable asset rather than a raw data dump.
Use Cases of Google Image Scraper API Beyond SEO
Most discussions around a Google Image Scraper API focus on search visibility. In reality, its applications extend far beyond SEO. Structured access to Google image search data supports competitive intelligence, brand monitoring, and large-scale dataset creation.
Competitive Visual Monitoring
In visual-driven industries such as eCommerce, fashion, travel, and consumer electronics, image ranking often influences user perception. A Google Image API allows teams to track which competitors dominate image SERP results for high-intent queries.
By using a google images api or image search api, businesses can:
- Monitor shifts in image ranking positions
- Identify emerging competitors gaining visual exposure
- Analyze which domains consistently appear in top image search results
Instead of manually checking thumbnails, structured extraction delivers consistent image ranking data across multiple keywords and markets.
Brand and Product Tracking
Brand visibility is no longer limited to text search. Logos, product photos, and marketing visuals frequently appear in Google image search results.
When you scrape Google Images using a reliable API, you can track:
- Where branded images are appearing
- Whether unauthorized sources are ranking for your assets
- How product imagery performs across commercial queries
This type of monitoring helps protect brand integrity and maintain control over visual representation.
Dataset Collection for AI and Visual Search API Models
For teams building computer vision systems or training models, structured image data is essential. A Google Image Scraper API can collect labeled images, associated keywords, and contextual metadata.
When integrated with a visual search api workflow, extracted image SERP results become a scalable source of structured visual data. This supports research, product development, and machine learning initiatives without relying on unstable manual scraping methods.
Conclusion
Image search is no longer a secondary layer of visibility. It is a structured search environment with its own ranking logic, competitive landscape, and data signals. Businesses that ignore it miss a measurable portion of search behavior.
A reliable Google Image Scraper API changes how teams access and use visual search data. Instead of dealing with unstable scripts or inconsistent outputs, you gain structured access to image SERP results, ranking positions, source domains, and associated metadata. That consistency makes large-scale analysis practical.
Whether the goal is competitive monitoring, brand tracking, or dataset collection for a visual search api model, disciplined extraction matters. Scaling responsibly, cleaning data properly, and structuring storage correctly ensures that insights remain accurate over time.
Google image search will continue evolving. Layouts shift. Ranking factors adjust. New visual formats appear. The advantage belongs to teams that treat image data as a strategic asset rather than a manual task.
When implemented thoughtfully, a Google Image Scraper API becomes more than a scraping tool. It becomes infrastructure for reliable visual intelligence.
FAQs
What is a Google Image Scraper API?
A Google Image Scraper API is a structured solution that retrieves data from Google image search results in a clean, machine-readable format. It extracts image URLs, source links, image ranking positions, and related metadata without relying on fragile front-end scraping scripts.
Is it legal to scrape Google Images?
Legality depends on how the data is accessed and used. Extracting publicly available image SERP results for analysis is different from downloading or redistributing copyrighted images. Always review platform terms and ensure compliance with local regulations before you scrape Google Images.
What data can you extract from image SERP results?
You can extract image URLs, thumbnails, source domains, ranking positions, alt context, and associated keywords using a Google Image Scraper API.
Can I scrape Google Images without getting blocked?
Basic scripts often trigger rate limits or CAPTCHA checks. Structured request handling and controlled query management are essential for stability at scale.
Why use an image search API instead of manual scraping?
An image search api offers consistent, scalable access to image SERP results, making large-scale data collection practical and reliable.