Table of Contents
Table of Contents
Web scraping has developed as a crucial resource for both businesses and developers. It allows you to collect large volumes of data from websites, which may then be used for a variety of purposes, including market research, pricing comparison, trend analysis, and the creation of automated systems. Mastering web scraping in JavaScript offers a world of possibilities for developers looking to enhance their projects with automated data collection.
This blog will dive into how to master web scraping in JavaScript, focusing on the best tips, tools, and strategies. Whether you’re a beginner or looking to improve your skills, this guide will help you understand how to extract data from websites using JavaScript effectively. We’ll also go over the best web scraping tools and cover essential tips for successful scraping.
What is Web Scraping?
Web scraping collects website data by reviewing their HTML content and extracting relevant information. Web scraping eliminates the need to copy and paste data, saving time and effort manually. It is every day used for a variety of purposes, including market research, pricing comparison, and trend analysis.
Why Use JavaScript for Web Scraping?
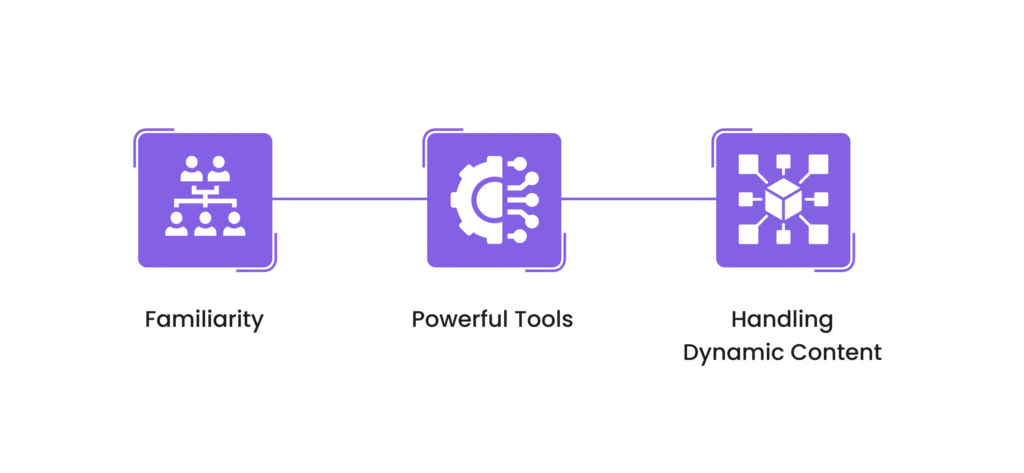
JavaScript is one of the most popular programming languages and is frequently used for website client-side scripting. But why use JavaScript for web scraping?
- Familiarity: JavaScript is already widely used by developers, so it’s easier to get started with web scraping if you’re already familiar with the language.
- Powerful Tools: JavaScript offers many powerful tools and libraries specifically designed for web scraping.
- Handling Dynamic Content: Many websites today use JavaScript frameworks to load dynamic content. Using JavaScript allows you to interact with these websites seamlessly.
By leveraging JavaScript, you can extract data from dynamic web pages and JavaScript-heavy websites, making it an ideal choice for web scraping.
Getting Started with Web Scraping in JavaScript
Initially, when embarking on web scraping in JavaScript, you should establish your environment and familiarize yourself with the crucial libraries.
◆ Setting Up Your Environment
First, make sure you have Node.js installed on your computer, it allows you to run JavaScript outside of the browser. You can download it from the official website. After completing the installation, create a directory for your project and use npm to install the required libraries.
◆ Key Libraries for Web Scraping
There are several JavaScript libraries you can use for web scraping, but the three most popular ones are Puppeteer, Cheerio, and Axios. These libraries offer different functionalities, depending on whether you are scraping simple static sites or more complex, dynamic ones.
Top Tools for Web Scraping in JavaScript
When it comes to web scraping in JavaScript, choosing the right tools is essential. Here are the top tools that will make your job easier:
↣ Puppeteer
Puppeteer is a widely used framework for Node.js that offers a comprehensive API for managing Chrome or Chromium through the DevTools Protocol. It can handle JavaScript-heavy websites and dynamic content, making it an effective web scraper.
Key features:
- Automates browsing and interaction with web pages.
- Captures screenshots and PDFs of web pages.
- Gathers dynamic content by waiting for the full loading of the page.
↣ Cheerio
Cheerio is a fast and flexible library that works with static HTML content. It offers a syntax similar to jQuery to select and retrieve information from web pages.
Key features:
- Parses and manipulates static HTML.
- Fast and lightweight.
- Ideal for scraping websites that don’t require JavaScript to load data.
↣ Axios
Axios is a promise-based HTTP client for making requests to web pages. It is commonly used alongside Cheerio to fetch HTML content from websites. It makes the task of sending GET requests and analyzing responses more straightforward.
↣ Nightmare
Nightmare is another great tool that works similarly to Puppeteer but focuses on high-level browser automation. It’s especially useful for scraping dynamic web pages and interacting with websites that rely heavily on JavaScript.
Best Practices for Web Scraping in JavaScript

To successfully scrape websites with JavaScript, some best practices must be followed. These measures not only enhance the efficiency of your scraping activities but also prevent your scraper from being blocked.
Handling Dynamic Web Pages
JavaScript is used in the building of many websites today to enable dynamic content loading. Because of this, scraping can be a bit difficult because the data you require might not be in the initial HTML. In these situations, using tools like Puppeteer, which renders the page like a real browser would, is helpful.
Make sure to:
- Wait for the content to load before scraping.
- Use appropriate delays to avoid overwhelming the server.
Dealing with Anti-Scraping Mechanisms
Websites often have anti-scraping measures in place, such as CAPTCHAs, rate limiting, or blocking IP addresses after a certain number of requests. To overcome these challenges:
- Rotate IP addresses using proxies.
- Use user-agent rotation to simulate real users.
- Be respectful of a website’s terms of service.
Respecting Robots.txt
Always check a website’s robots.txt file to see what content can and cannot be scraped. Ignoring this can lead to legal issues or getting blocked by the website. Respect the rules set out in this file to avoid any trouble.
Data Validation and Cleaning
When scraping large databases, it is essential to ensure that whatever data you collect is correct and clean. Always validate data to make sure that it is useable and free of duplicates and errors. Cleaning the data during or after scraping guarantees that the information may be used effectively.
Common Challenges and How to Solve Them
Web scraping comes with several challenges, especially when dealing with JavaScript-heavy websites or sites with anti-scraping features.
JavaScript-Heavy Websites:
For websites that load data dynamically, headless browsers such as Puppeteer can help in scraping the required content. Puppeteer can simulate real user interaction and retrieve data that appears after the initial page load.
Rate Limiting and Throttling:
A variety of websites set limits on the number of requests allowed from an individual IP address during a defined timeframe. To avoid getting blocked:
- Limit your requests to simulate natural human browsing patterns.
- Utilize proxies to spread requests over a range of IP addresses.
Legal Considerations for Web Scraping
Before scraping any website, it’s important to understand the legal implications. Not all websites allow scraping, and some have strict rules in place to protect their data. Always:
- Check the website’s terms of service to see if scraping is allowed.
- Respect intellectual property laws and privacy regulations.
- Use the robots.txt file as a guide for what you can and cannot scrape.
Web scraping is a powerful tool, but it’s essential to use it responsibly and ethically to avoid legal complications.
Conclusion
Mastering web scraping in JavaScript requires the use of the right tools, knowledge of best practices, and an understanding of the issues that may arise. Tools such as Puppeteer and Cheerio efficiently scrape dynamic and static web pages. Always follow ethical guidelines, respect a website’s robots.txt file, and ensure that your scraping actions are lawful.
With these techniques and tools in hand, you’ll be well on your way to mastering web scraping with JavaScript. Whether you’re collecting data for market research, price tracking, or SEO analysis, the web scraping skills you learn will be very helpful in today’s data-driven world.
FAQs
What is web scraping in JavaScript?
Web scraping in JavaScript is the process of using scripts to extract data from websites automatically. It’s popular because JavaScript can handle both static and dynamic content, making it versatile for modern websites.
Which are the best tools for web scraping in JavaScript?
The top tools are Puppeteer for scraping dynamic pages, Cheerio for handling HTML in a jQuery-like way, and Axios for making HTTP requests. These tools are easy to use and widely supported.
Can JavaScript scrape dynamic content?
Yes, JavaScript, with tools like Puppeteer, can scrape dynamic content loaded via JavaScript frameworks (like React or Angular), which isn’t possible with traditional methods.
What are the challenges of web scraping in JavaScript?
Common challenges include dealing with CAPTCHAs, handling dynamic content, and avoiding IP bans. Proper setup, such as using proxies and automation tools, can help bypass these issues.