Table of Contents
Table of Contents
Web scraping means pulling information from websites and turning it into something you can actually use. People often rely on it for things like tracking prices, studying markets, following news, or digging into data trends.
Python has become the go-to language for scraping because it’s both beginner-friendly and packed with solid libraries. You can use Requests to fetch web pages, BeautifulSoup to sift through HTML, and tools like Selenium or Playwright if the site runs heavily on JavaScript.
What makes Python so useful is the mix of simplicity and power. With just a little code, you can set up scripts that collect data automatically, adapt to different page layouts, and store results in formats like CSV, Excel, or even straight into a database.
That said, scraping isn’t a free-for-all. You still need to be mindful: respect site policies, avoid hammering servers with too many requests, and stay within legal boundaries.
In this guide, we’ll cover the basics of scraping with Python, walk through the key tools you’ll need, and share some best practices to help you build scrapers that are both efficient and reliable.
Why Python is the Go-To Choice for Web Scraping
There are many programming languages you could use for scraping, but Python stands out. Here’s why it has become the first choice for developers and data professionals:
1. Easy to Read and Write
Python’s syntax is simple. You don’t need advanced programming knowledge to start writing scrapers. Even a few lines of code are enough to fetch and parse a web page.
2. Rich Library Support
- Requests for handling HTTP requests
- BeautifulSoup and lxml for parsing HTML
- Selenium and Playwright for working with dynamic websites
This ecosystem saves time and effort — you rarely have to build scraping tools from scratch.
3. Strong Community and Resources
Python has one of the largest developer communities. Most common scraping challenges already have tutorials, open-source code, or discussions online. This makes troubleshooting much easier.
4. Perfect for Data Handling
Scraped data often needs cleaning and analysis. Python connects directly with Pandas, NumPy, and other data libraries, allowing you to process and analyze the data without switching languages.
5. Flexibility for Any Project
From small scripts that pull a few lines of text to large-scale scraping projects that gather millions of records, Python can handle it all.

Essential Libraries You Can’t Ignore
Python’s popularity in web scraping comes down to its libraries. Among the many available, three stand out as must-haves: Requests, BeautifulSoup, and Selenium.
Requests are where it all begins. Without sending an HTTP request, you don’t get the HTML to work with. This library makes that step simple and clean. A single function call can fetch a page, and from there, you can start exploring the response.
BeautifulSoup comes next. Once you have the raw HTML, you need a way to sift through the tags and pull out meaningful data. BeautifulSoup provides that functionality. It lets you navigate the document tree, search by elements, and extract exactly what you need—even if the page structure isn’t perfect.
Selenium handles what the other two can’t. Many websites rely on JavaScript to display data, and a basic request won’t capture that. Selenium solves the problem by automating a real browser. It loads the page just like a user would, making it possible to interact with buttons, dropdowns, and dynamically loaded content.
Together, these three tools cover most scraping scenarios—from simple static pages to complex, script-heavy websites. If you’re serious about web scraping in Python, they form the core toolkit you’ll keep returning to.
Handling Dynamic Content and JavaScript
If static websites are straightforward to scrape, modern websites are a different story. A growing number of platforms rely on JavaScript to load their content. That means the data you see on the screen may not exist in the raw HTML at all. This is where many beginners get stuck—your code fetches the page, but the information you want is missing.
Understanding What’s Happening
When you load a site, the server often sends a minimal HTML structure, and then JavaScript fills in the blanks by fetching data from other sources. For example, an e-commerce page may only load product titles and prices after you scroll down or click a filter. So, unless you account for this behavior, your scraper will come up empty.
Method 1: Track API Requests
The first and most efficient strategy is to check if the site is pulling data from a backend API. You can inspect this using the Network tab in your browser’s developer tools. If you find a clean JSON or XML endpoint, you’re in luck—skip scraping altogether and connect to that API directly using Python’s requests library. This approach is fast, reliable, and far less resource-heavy.
Method 2: Automate the Browser
When no usable API is exposed, you’ll need a way to render JavaScript. This is where tools like Selenium or Playwright step in. These libraries allow Python to control a browser session, wait for content to load, and extract the final rendered HTML.
- Selenium is widely used and works across multiple browsers, though it can be slow.
- Playwright is newer, faster, and designed for handling complex, modern web apps.
Both are more demanding than simple requests, but they’re indispensable for scraping sites that hide data behind JavaScript.
Avoiding Blocks and CAPTCHA
If you’ve done any serious scraping, you already know that the technical part isn’t always the hardest. The real challenge is keeping your scraper alive long enough to finish the job. Websites don’t just hand over their data—they actively protect it. Blocks, rate limits, and CAPTCHAs are the most common obstacles, and learning how to deal with them is just as important as writing clean code.
Why Websites Block Scrapers
From the site’s point of view, automated scraping looks like abuse. Dozens of requests coming in every second from the same IP address is not normal human behavior. To protect servers and user experience, many websites monitor traffic patterns. Once they see something unusual, they may:
- Throttle your requests (slow responses down).
- Show CAPTCHAs to test if you’re a real person.
- Block your IP completely.
Understanding why you’re being blocked is the first step toward avoiding it.
Strategies That Actually Work
Here are a few proven techniques that experienced developers rely on:
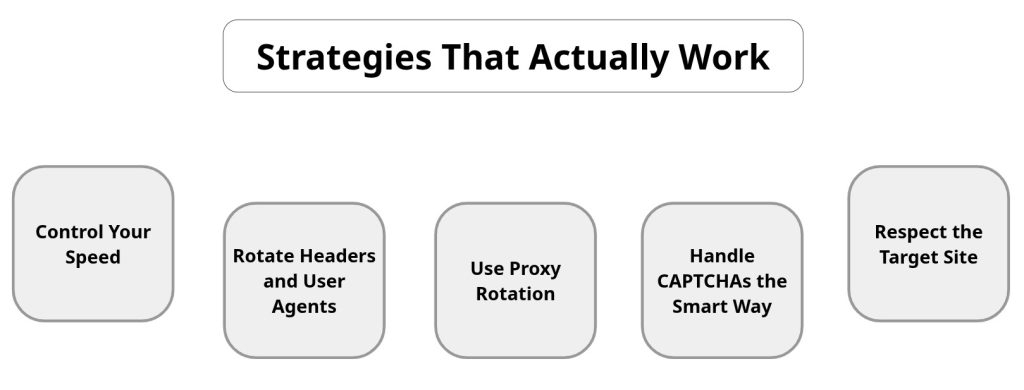
- Control Your Speed
Don’t hammer the server. Add random delays or exponential backoff between requests. Slower scraping might feel inefficient, but it’s far more sustainable. - Rotate Headers and User Agents
If every request carries the exact same browser fingerprint, it’s obvious you’re running a bot. Randomizing your user agents (e.g., Chrome, Firefox, Safari on different devices) makes your traffic look natural. - Use Proxy Rotation
A single IP address sending thousands of requests is an easy target. Rotating proxies spreads your requests across multiple IPs, making them harder to detect. Residential or rotating proxies tend to perform best for scraping at scale. - Handle CAPTCHAs the Smart Way
You have two options: integrate a CAPTCHA-solving service, or prevent them from appearing in the first place. The second option is always better. Clean headers, natural request patterns, and a realistic browsing flow (like waiting for page loads) can reduce how often CAPTCHAs appears. - Respect the Target Site
This is often overlooked. Read the site’s robots.txt file, avoid scraping sensitive data, and keep request volumes within reason. Responsible scraping not only helps avoid bans but also reduces the ethical and legal risks.
Cleaning and Storing Scraped Data Efficiently
Scraping data is only half the job. Once you have it, the next step is cleaning and storing it so that it can actually be used for analysis, reporting, or other applications. Raw data from websites often contains extra HTML tags, inconsistent formatting, missing values, or duplicates. Handling these issues properly ensures your results are accurate and reliable.
Cleaning the Data
Data cleaning involves standardizing formats, removing unnecessary information, and filling or removing missing values. For example:
- Strip out HTML tags from text.
- Convert dates into a standard format.
- Remove duplicate entries to avoid skewed results.
- Handle empty or missing fields intelligently.
Python provides tools like Pandas for cleaning and structuring data efficiently. Pandas makes it easy to filter, transform, and analyze scraped datasets with just a few lines of code.
Storing the Data
Once cleaned, the data needs to be stored in a format that suits your project. Common options include:
- CSV or Excel files – Simple, readable, and easy to share.
- Databases (MySQL, PostgreSQL, MongoDB) – Best for larger datasets or applications that require fast querying.
- JSON files – Useful for structured hierarchical data, such as nested product information.
Choosing the right storage method depends on your goals. Small-scale scraping can work fine with CSV or Excel, but larger projects benefit from databases that allow for fast access and scalability.

Real-World Use Cases and Examples
Web scraping isn’t theory—it’s something people use daily to solve practical problems. Here are a few areas where it makes the biggest impact:
- E-commerce & Pricing
Online retailers keep an eye on competitors’ prices to stay competitive. A scraper can track hundreds of products automatically and update a pricing dashboard in real time. - Market & Consumer Insights
Brands analyze customer reviews, ratings, and social conversations to understand trends. Scraping this data helps companies spot what buyers actually care about. - News & Content Aggregation
Many apps bring together headlines or travel deals from dozens of websites. Behind the scenes, scraping pulls that data into one place for users to browse easily. - Research & Personal Projects
Students gather data for studies, investors track stock prices, and journalists collect public records. These small-scale projects show how accessible scraping can be.
The versatility of web scraping in Python is what ties all these cases together. Whether it’s a quick script for one dataset or a large-scale pipeline collecting millions of records, the same techniques adapt to the goal.
Final Thoughts
Web scraping is more than just a coding exercise—it’s a practical skill that opens up access to valuable data across industries. From monitoring prices and gathering market insights to powering research and automation, it has proven itself as a tool with real impact.
The key is balance. A good scraper doesn’t just grab data; it does so efficiently, responsibly, and in a way that avoids unnecessary blocks or errors. Cleaning, storing, and maintaining that data is just as important as collecting it in the first place.
With the flexibility of web scraping in Python, developers can start small and scale up as needed. What begins as a simple script can grow into a full pipeline supporting business intelligence or large-scale analytics.
In the end, success comes down to knowing your tools, respecting the websites you work with, and building scrapers that are sustainable over time. If you approach it with patience and attention to detail, scraping isn’t just possible—it becomes a reliable part of your data toolkit.
best python scraping tools Google data extraction Google SERP scraping Google web scraping python automation scraping python requests scraping python scraper code python selenium scraping Python web scraping scrape google search python web scraping guide web scraping python tutorial web scraping tricks