Table of Contents
Table of Contents
Teams usually turn to scraping Google News for one simple reason: speed. News surfaces trends, emerging topics, and market signals earlier than most other channels. Waiting for reports or manually checking headlines is slow, so scraping becomes the shortcut to continuous visibility.
At first, the approach feels efficient. A script pulls headlines, extracts links, and feeds a dashboard or spreadsheet. The results look usable. The friction appears later.
Google News is a dynamic environment. Layouts shift. Story clusters evolve. Response patterns change without notice. What worked reliably during testing can become unstable once scraping runs at scale. This is where expectations need to stay grounded, a point frequently highlighted in any practical Google News API guide.
Scraping Google News is not just about collecting data. It is about handling variability, preventing breakage, managing request limits, and maintaining extraction logic over time. The effort is often underestimated, especially when projects move from experimentation to production workflows.
This article focuses on that practical reality. Instead of presenting scraping as a quick tactic, we examine why teams choose it, where complications arise, and what needs to be considered before relying on scraped Google News data in real systems.
Why Teams Scrape Google News Data

Most teams don’t start by deciding to scrape Google News. They arrive there after realizing that important signals are showing up in the news before they appear anywhere else. When timing matters, waiting is not an option.
Scraping becomes the fastest way to stay close to what is unfolding.
Early Trend Detection
Google News reacts quickly to change. When a new topic begins to gain attention, coverage often appears across multiple publishers within hours. Scraping allows teams to observe these early movements while the story is still forming.
This is not about chasing viral headlines. It is about spotting patterns before they become obvious. When the same topic starts appearing across different outlets, it usually signals something worth paying attention to.
Competitive Monitoring
Competitor activity often surfaces indirectly through news coverage. Announcements, partnerships, funding rounds, and leadership changes are reported long before they show up in traditional competitive analysis tools.
By scraping Google News, teams can watch how often competitors appear, which publications are covering them, and how the narrative shifts over time. These signals help teams understand momentum, not just presence.
Content Research and Editorial Signals
For content and SEO teams, Google News reflects editorial priorities in real time. Headlines reveal how topics are framed, which angles publishers choose, and how language evolves as a story develops.
Scraping this data supports content decisions that are grounded in what editors are actually publishing, not assumptions. It turns news coverage into a signal source rather than a reading exercise.
Curious about real-time news monitoring? Explore how teams stay updated without constantly refreshing dashboards.
Key Challenges When Scraping Google News
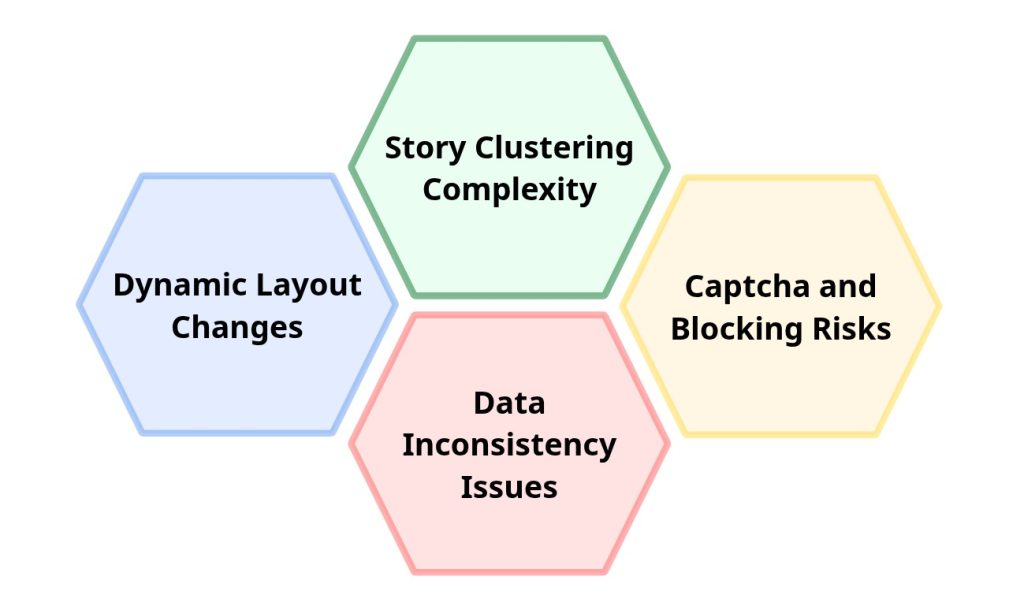
Scraping Google News appears straightforward at first glance. Headlines, links, timestamps. Simple. In practice, the environment behaves very differently from a static webpage. The challenges are not always visible during early testing but become obvious once scraping runs continuously or at scale.
Dynamic Layout Changes
Google News is not designed as a fixed structure. Layout components, HTML hierarchy, and class names can change without warning. Even small interface adjustments may break selectors that previously worked reliably.
A scraper that performs well today can silently fail tomorrow, returning incomplete or empty datasets. Maintaining extraction logic becomes an ongoing requirement rather than a one-time setup task.
Story Clustering Complexity
Google News groups related articles into clusters that evolve in real time. As new coverage appears, stories merge, shift position, or reorganize entirely. This behavior complicates scraping logic.
Extracted results may vary between requests even when the same query is used. Articles can move within clusters, disappear temporarily, or reappear under different groupings. Handling this fluid structure requires more than basic HTML parsing.
Captcha and Blocking Risks
Automated requests often trigger protective mechanisms. Rate limits, captchas, IP blocking, and response throttling are common challenges when scraping Google properties.
Without careful request management, scrapers may encounter:
- sudden access denials
- incomplete responses
- inconsistent loading behavior
Mitigating these risks typically involves proxy rotation, throttling controls, and retry strategies, all of which increase system complexity.
Data Inconsistency Issues
Unlike structured APIs, scraped data does not guarantee consistency. Missing fields, variable timestamp formats, truncated snippets, and unpredictable element placement are frequent issues.
These inconsistencies introduce downstream problems. Dashboards may display incorrect values. Alerts may misfire. Historical datasets may contain gaps that distort analysis.
Scraping workflows must therefore include validation, normalization, and error-handling layers to maintain usable data quality.
Working with news data in Python? Read more about the Google News API Python setup to get started quickly and correctly.
Technical Considerations Before Scraping
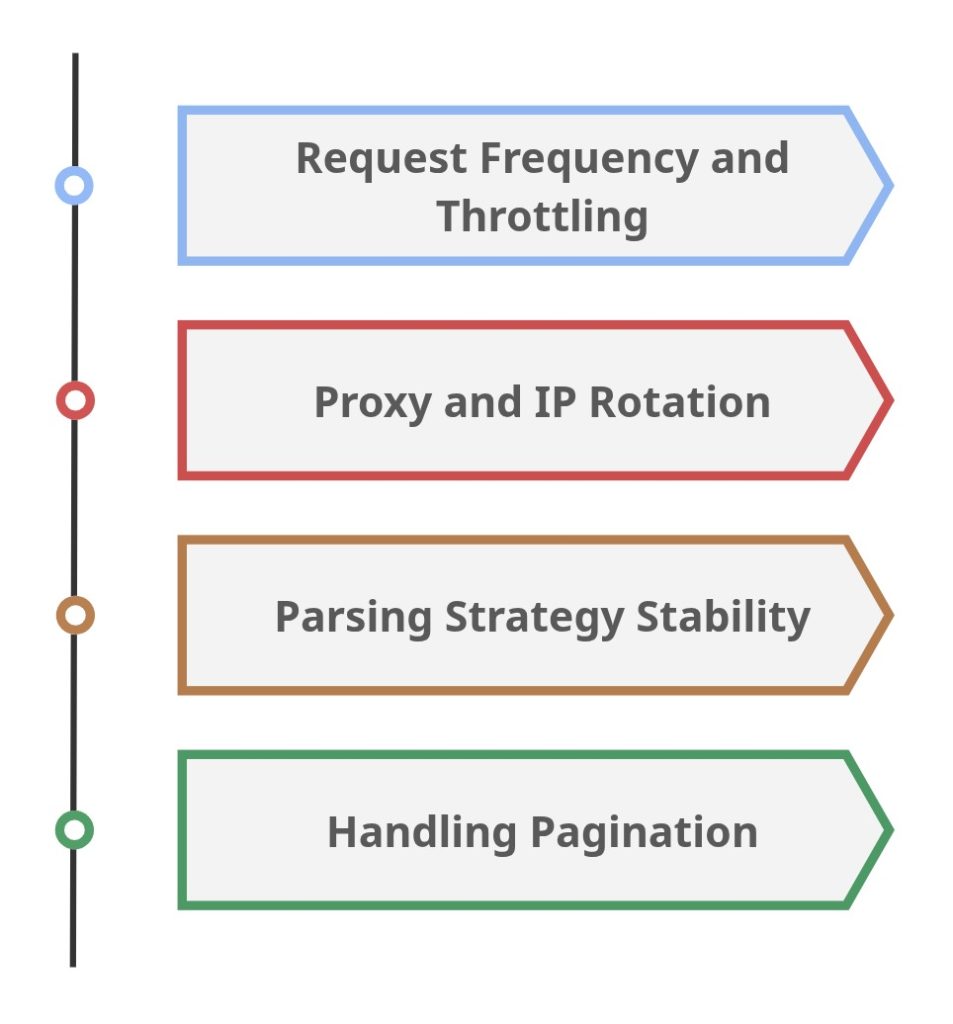
Before scraping Google News at scale, technical decisions start to matter more than the scraping logic itself. A script that works in a controlled test environment can behave very differently once request volume increases or execution becomes continuous. Planning for these factors early prevents instability later.
Request Frequency and Throttling
Uncontrolled request patterns are one of the fastest ways to trigger blocking mechanisms. Google News reacts to abnormal traffic behavior, especially when repeated queries originate from the same IP within short intervals.
Managing request frequency is less about speed and more about sustainability. Throttling strategies help maintain access stability while reducing the likelihood of captchas, temporary bans, or response degradation.
Well-paced scraping routines typically outperform aggressive ones over longer durations.
Proxy and IP Rotation
As scraping intensity increases, relying on a single IP address becomes risky. Repeated automated requests can lead to rate limiting or outright blocking.
Proxy and IP rotation distribute traffic across multiple addresses, lowering detection risk. However, this introduces its own layer of complexity. Proxy quality, rotation logic, failure handling, and geographic relevance all influence scraping reliability.
Poor proxy management can create more instability than it solves.
Parsing Strategy Stability
Parsing logic that depends on fragile selectors often breaks when layout changes occur. Google News does not guarantee fixed HTML structures, which means extraction rules must tolerate variation.
More resilient parsing strategies focus on structural patterns rather than exact class names. Validation layers and fallback rules also help maintain data continuity when elements shift or partially load.
Without stability safeguards, scrapers require constant manual fixes.
Handling Pagination
Google News result sets can span multiple pages, especially for broader queries. Pagination handling must account for navigation logic, dynamic loading behavior, and potential duplication across pages.
Improper pagination management can lead to:
- missing articles
- duplicated entries
- inconsistent dataset sizes
Reliable pagination logic ensures complete coverage while preserving data accuracy across repeated scraping cycles.
Methods for Scraping Google News
There is no single “correct” way to scrape Google News. The approach usually depends on project scale, reliability needs, and how much infrastructure a team is prepared to maintain. Below are the most common methods used in practice.
Python Based Scraping
Python remains a popular choice due to its mature ecosystem and flexible parsing libraries. Tools like BeautifulSoup and Scrapy are frequently used to extract headlines, links, timestamps, and snippets from HTML responses.A simplified example using requests and BeautifulSoup:
This illustrates the basic concept: fetch → parse → extract.
In reality, Google News pages often require more robust handling. Dynamic loading, nested structures, and shifting selectors can quickly complicate this workflow.
Headless Browser Approach
Google News frequently relies on JavaScript-rendered elements. When static HTTP requests fail to capture fully loaded content, headless browsers become necessary.
Tools such as Playwright or Puppeteer simulate real user behavior, allowing scripts to wait for page rendering before extraction.
Example using Playwright (Python):
This method improves extraction accuracy but introduces higher resource usage and operational complexity.
Third Party Scraping Tools
Non-code tools such as Octoparse, ParseHub, and similar platforms offer visual scraping interfaces. These tools reduce development effort but still face the same structural challenges:
- layout changes
- captchas
- blocking risks
- inconsistent data extraction
They are often used for quick experiments or small-scale data collection rather than long-term automated systems.
Example Scraping Workflow
Regardless of the tools or language used, most Google News scraping setups follow a similar operational pattern. The differences lie in how resilient each step is when conditions change.
Defining the Query
The workflow begins by determining what should be monitored. This typically includes selecting keywords, topics, or entities that reflect the project’s objective. A vague query often produces noisy datasets, while an overly narrow one may miss relevant coverage.
Effective scraping starts with clarity around:
- search intent
- keyword variations
- geographic relevance
Fetching the Page
Once the query is defined, the scraper sends requests to retrieve Google News result pages. This stage appears simple but quickly becomes sensitive to request headers, user-agent configuration, throttling, and blocking behavior.
At scale, request management becomes as important as extraction logic.
Parsing the Response
After retrieval, the HTML or rendered content is parsed to locate relevant elements. Headlines, publishers, timestamps, and URLs are extracted based on structural patterns or selectors.
This step is often the most fragile. Even minor layout adjustments can break parsing rules and silently reduce data quality.
Extracting Structured Data
Parsed elements are converted into structured records. Fields such as title, source, publication time, and link are normalized for storage or downstream analysis.
Without normalization, scraped datasets tend to contain inconsistencies that complicate reporting and automation.
Storage and Validation
The final step involves storing results in databases, dashboards, or monitoring systems. Validation checks help detect missing fields, duplicates, or extraction failures before errors propagate.
Over time, validation layers become essential for maintaining dataset integrity.
Before building your workflow, it helps to review the Google News API features.

Common Data Points Extracted
When scraping Google News, the goal is rarely to capture entire articles. Most workflows focus on extracting visible metadata that reflects how stories appear and evolve within news results. These data points form the foundation for monitoring, analysis, and trend detection systems.
Headlines
Headlines are typically the primary extraction target. They capture how a story is framed at a specific moment and often reflect the dominant keywords associated with emerging topics.
Changes in headline wording can indicate:
- narrative shifts
- evolving story angles
- publisher-specific emphasis
For many teams, headline tracking becomes a proxy for understanding topic momentum.
Publishers
Publisher information identifies the source behind each article. Scraped publisher data helps teams evaluate coverage distribution, source diversity, and media visibility patterns.
This is especially useful when analyzing:
- which outlets surface stories first
- how coverage spreads across publishers
- credibility and authority signals
Timestamps
Publication timestamps provide temporal context. Scraping this field allows teams to measure content freshness, detect breaking developments, and reconstruct coverage timelines.
Timestamp analysis commonly supports:
- trend acceleration tracking
- alert prioritization
- historical comparisons
URLs
Article URLs connect metadata to the original source. Scraped links are essential for validation, content review, and downstream processing such as archiving or enrichment.
Reliable URL extraction also helps prevent duplication and broken reference chains.
Thumbnails
Thumbnail images, when available, are often collected for visual presentation in dashboards or user-facing interfaces. While less critical for analysis, thumbnails improve readability and context in aggregated news displays.
Their availability and format, however, can vary across results.

Final Thoughts
Scraping Google News often begins as a practical shortcut. It provides quick access to headlines, publishers, and timestamps without requiring external services or subscriptions. In controlled experiments or small-scale projects, this approach can work surprisingly well.
The reality shifts as systems grow.
Google News is a dynamic environment where layouts evolve, clustering changes, and access restrictions tighten without notice. What initially feels like a lightweight data collection method can gradually turn into an ongoing maintenance commitment. Stability becomes harder to preserve, and the effort required to keep scrapers functioning increases over time. At this stage, teams often start considering alternatives such as a Google News Search API to improve consistency.
This does not mean scraping is inherently flawed. It means expectations must remain aligned with sustainability. Short-term research tasks and exploratory analysis may justify the tradeoffs. Long-term monitoring systems, automated alerts, and production workflows demand a level of reliability that scraping alone often struggles to provide.
The key decision is not whether scraping works today. It is whether the approach remains practical months from now.
Teams that evaluate this question early tend to avoid repeated cycles of breakage, fixes, and infrastructure adjustments. Choosing a strategy based on durability rather than convenience ultimately determines how effectively Google News data supports analysis, monitoring, and decision-making workflows over time.